
Config Schema#
Dagster includes a system for strongly-typed, self-describing configuration schemas.
Relevant APIs#
| Name | Description |
|---|---|
ConfigSchema | See details with code examples in the API documentation. |
Overview#
The configuration schema helps:
- Catch configuration errors before pipeline execution.
- Improve pipeline documentation and therefore help learn how to operate a pipeline based on config schema.
The config system supports structured types for complex configurations. Notable entries include:
Field- the basic building block.Shape- for well defined dictionaries.Permissive- for allowing untyped dictionaries.Selector- to allow choosing one of N.StringSource- to allow loading from environment.Enum- for choosing from a well defined set of values.
These are documented in the API Reference with examples.
Configuring a Solid#
The most common objects to specify ConfigSchema for
are SolidDefinition and ResourceDefinition (see example code in Configuring a Resource).
This example shows how `config_schema can be used on a solid to control its behavior:
@solid(
config_schema={
# can just use the expected type as short hand
"iterations": int,
# otherwise use Field for optionality, defaults, and descriptions
"word": Field(str, is_required=False, default_value="hello"),
}
)
def config_example_solid(context):
for _ in range(context.solid_config["iterations"]):
context.log.info(context.solid_config["word"])
@pipeline
def config_example_pipeline():
config_example_solid()
Specifying Config Schema#
You can specify the config values in the following ways:
Python API#
You can specify the config values through run_config argument to execute_pipeline
def run_good_example():
return execute_pipeline(
config_example_pipeline,
run_config={"solids": {"config_example_solid": {"config": {"iterations": 1}}}},
)
Dagster validates the run_config against the config_schema. If the values violate the schema, it will fail at execution time. For example:
def run_bad_example():
# This run will fail to start since there is required config not provided
return execute_pipeline(config_example_pipeline, run_config={})
def run_other_bad_example():
# This will also fail to start since iterations is the wrong type
execute_pipeline(
config_example_pipeline,
run_config={"solids": {"config_example_solid": {"config": {"iterations": "banana"}}}},
)
Dagster CLI#
The config values can also be in YAML files like:
solids:
config_example_solid:
config:
iterations: 1
You can use the Dagster CLI dagster pipeline execute --config to run a pipeline with one or more YAML files.
Dagit#
You can also edit the config and execute a run in Dagit's Playground:
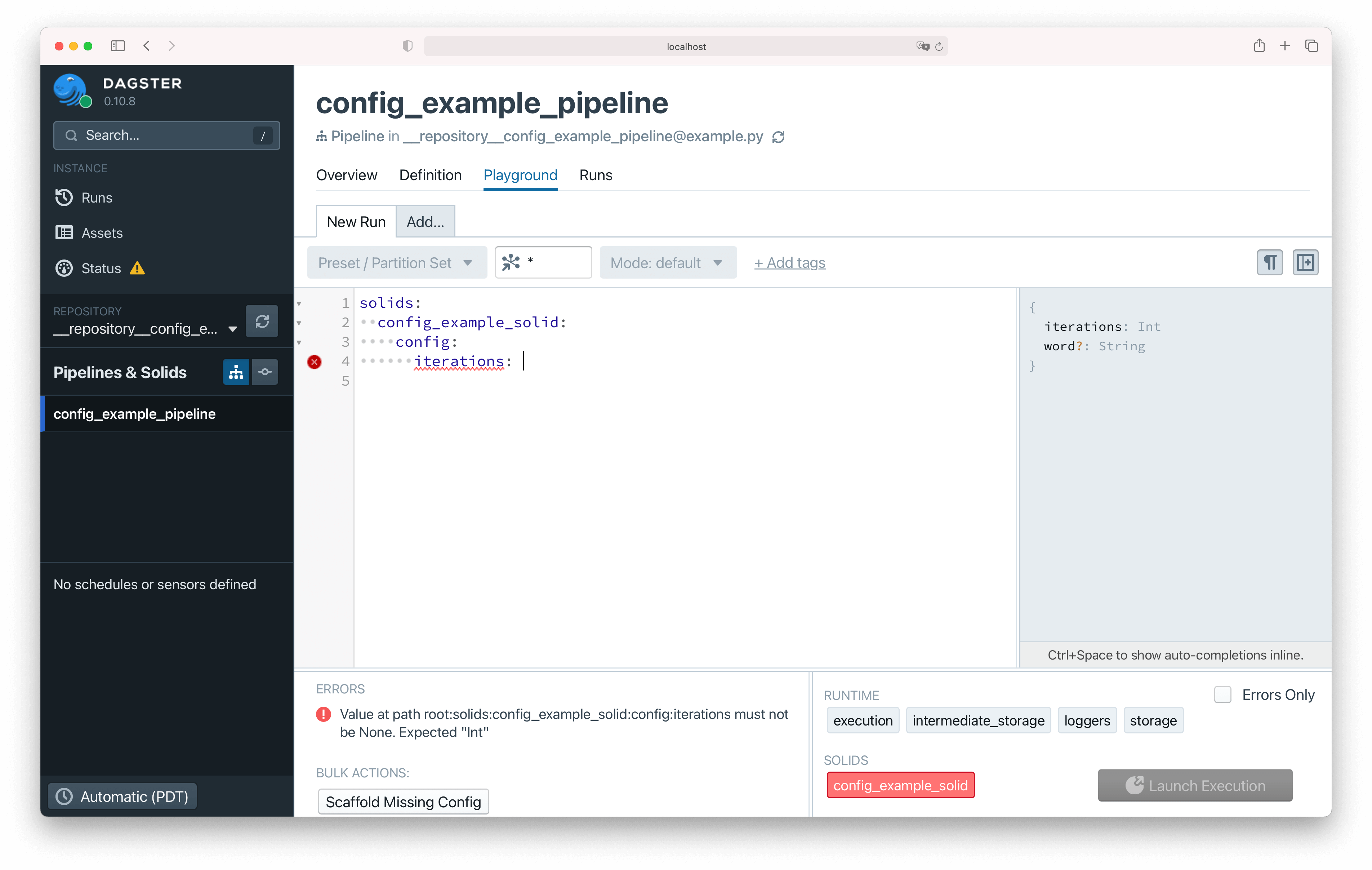
The config editor on the page comes with typeaheads, schema validation, and schema documentation. You can also click the "Scaffold Missing Config" button to generate dummy values based on the config schema.
Examples#
Configuring a Resource#
You can also configure a configure ResourceDefinition:
@resource(config_schema={"region": str, "use_unsigned_session": bool})
def s3_session(_init_context):
"""Connect to S3"""
And specify the configurations at runtime via a run config like:
resources:
key:
config:
region: us-east-1
use_unsigned_session: False
Config Mapping#
This example demonstrates how to use config mapping in Dagster to simplify complicated solid config schemas. Imagine you are launching many different invocations of a Spark job with similar cluster configurations, you might need to write something like:
solids:
solid_a:
config:
driver_cores: 2
driver_memory: "4g"
num_executors: 4
executor_cores: 4
executor_memory: "8g"
name: "job_a"
args: ["--record-src", "foo"]
solid_b:
config:
driver_cores: 2
driver_memory: "4g"
num_executors: 4
executor_cores: 4
executor_memory: "8g"
name: "job_b"
args: ["--record-src", "bar"]
...
As you can see, most of the configuration remains unchanged for solid_a and solid_b, which can get tedious if you have hundreds of copies.
With config mapping, you can create a @composite_solid to wrap your complicated solid(s), pin the shared config, and only expose name to users of the composite solid:
from dagster import Field, Shape, composite_solid, pipeline, repository, seven, solid
@solid(
config_schema={
"cluster_cfg": Shape(
{
"num_mappers": Field(int),
"num_reducers": Field(int),
"master_heap_size_mb": Field(int),
"worker_heap_size_mb": Field(int),
}
),
"name": Field(str),
}
)
def hello(context):
context.log.info(seven.json.dumps(context.solid_config["cluster_cfg"]))
return "Hello, %s!" % context.solid_config["name"]
def config_mapping_fn(cfg):
return {
"hello": {
"config": {
"cluster_cfg": {
"num_mappers": 100,
"num_reducers": 20,
"master_heap_size_mb": 1024,
"worker_heap_size_mb": 8192,
},
"name": cfg["name"],
}
}
}
@composite_solid(
config_fn=config_mapping_fn,
config_schema={"name": Field(str, is_required=False, default_value="Sam")},
)
def hello_external():
return hello()
@pipeline
def example_pipeline():
hello_external()
@repository
def config_mapping():
return [example_pipeline]
In this example, the hello solid has a complicated cluster config. With hello_external, we've pre-configured the cluster config and expose only a simplified config which we pass through to the inner hello solid.