
Data Science with Notebooks#
Fast iteration, the literate combination of arbitrary code with markdown blocks, and inline plotting make notebooks an indispensible tool for data science. The Dagstermill package makes it straightforward to run notebooks using the Dagster tools and to integrate them into data pipelines with heterogeneous solids: for instance, Spark jobs, SQL statements run against a data warehouse, or arbitrary Python code.
pip install dagstermill
Dagstermill lets you:
- Run notebooks as solids in heterogeneous data pipelines with minimal changes to notebook code
- Define data dependencies to flow inputs and outputs between notebooks, and between notebooks and other solids
- Use Dagster resources, and the Dagster config system, from inside notebooks
- Aggregate notebook logs with logs from other Dagster solids
- Yield custom materializations and other Dagster events from your notebook code
Our goal is to make it unnecessary to go through a tedious "productionization" process where code developed in notebooks must be translated into some other (less readable and interpretable) format in order to be integrated into production workflows. Instead, we can use notebooks as solids directly, with minimal, incremental metadata declarations to integrate them into pipelines that may also contain arbitrary heterogeneous solids.
Notebooks as solids#
Let's consider the classic Iris dataset (1, 2), collected in 1936 by the American botanist Edgar Anderson and made famous by statistician Ronald Fisher. The Iris dataset is a basic example in machine learning because it contains three classes of observation, one of which is straightforwardly linearly separable from the other two, which in turn can only be distinguished by more sophisticated methods.
Like many notebooks, this example does some fairly sophisticated work, producing diagnostic plots and a (flawed) statistical model -- which are then locked away in the .ipynb format, can only be reproduced using a complex Jupyter setup, and are only programmatically accessible within the notebook context.
We can simply turn a notebook into a solid using define_dagstermill_solid.
Once we create a solid, we can start to make its outputs more accessible.
import dagstermill as dm
from dagster import ModeDefinition, fs_io_manager, local_file_manager, pipeline
from dagster.utils import script_relative_path
k_means_iris = dm.define_dagstermill_solid(
"k_means_iris", script_relative_path("iris-kmeans.ipynb")
)
@pipeline(
mode_defs=[
ModeDefinition(
resource_defs={"io_manager": fs_io_manager, "file_manager": local_file_manager}
)
]
)
def iris_pipeline():
k_means_iris()
This is the simplest form of notebook integration -- we don't actually have to make any changes in the notebook itself to run it using the Dagster tooling. Just run:
dagit -f iris_pipeline.py
What's more, every time we run the notebook from Dagit, a copy of the notebook as executed will be written to disk and the path of this output notebook will be made available in Dagit:
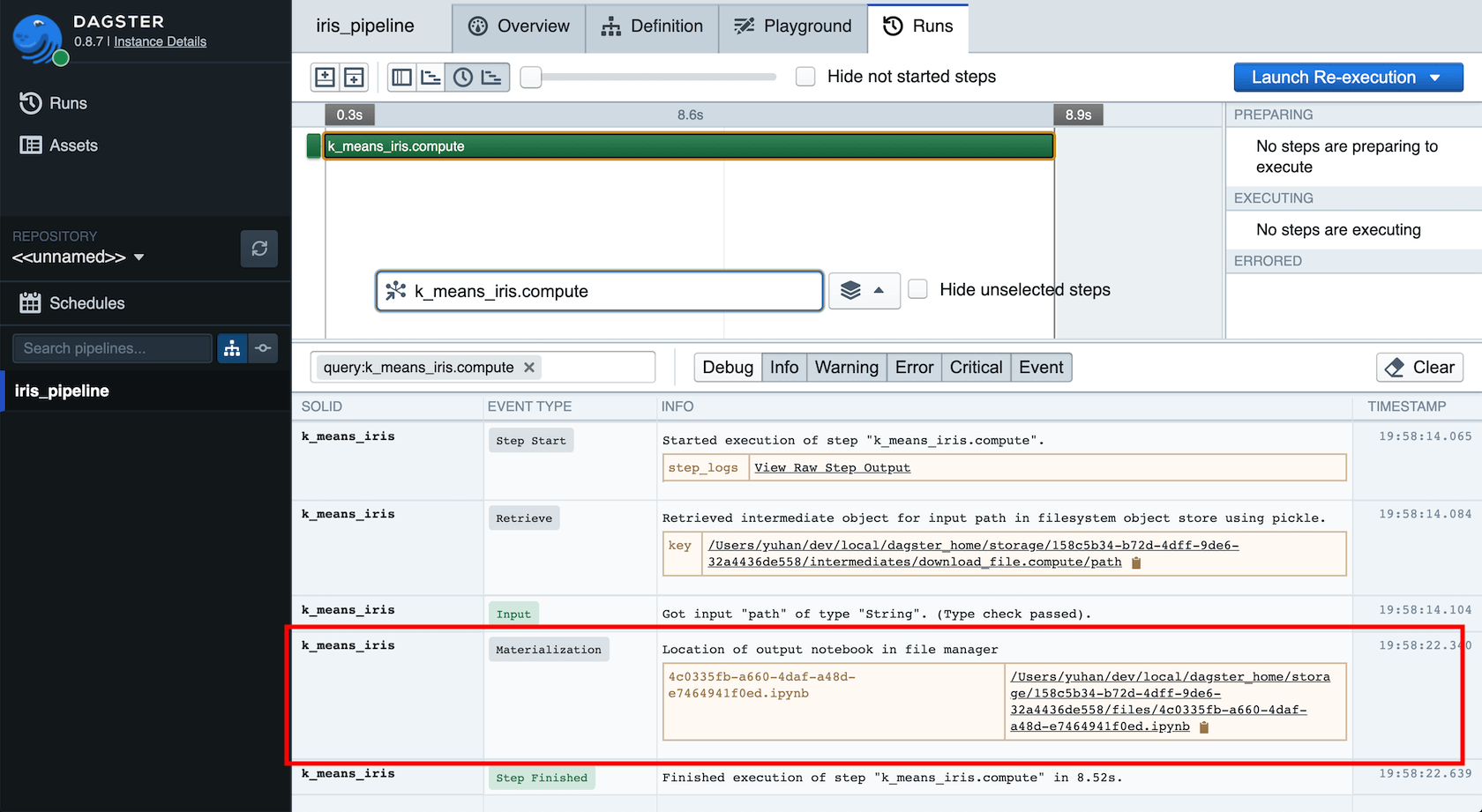
The output notebook is both a rich log of notebook computations as they actually occurred, including all inline plots and results, and also an important tool for interactive debugging. When a notebook fails, the output notebook can be used to determine the cause of the failure.
Expressing dependencies#
Notebooks often have implicit dependencies on external state like data
warehouses, filesystems, and batch processes. For example, even in our
simple Iris example we're making assumptions about data that's
available locally, in this case the iris.data file:
[2]:
ipython3
iris = pd.read_csv(
'iris.data',
...
)
The ability to express data dependencies between heterogeneous units of computation is core to Dagster, and we can easily make notebooks depend on upstream solids.
We'll illustrate this process by adding a non-notebook solid to our pipeline, which will take care of downloading the Iris data from the UCI repository. This is a somewhat contrived example; in practice, your notebook solids are more likely to rely on upstream jobs whose outputs might be handles to tables in the data warehouse or to files on S3, and your notebook will likely handle the task of fetching the data.
import dagstermill as dm
from dagster import InputDefinition, ModeDefinition, fs_io_manager, pipeline
from dagster.utils import script_relative_path
from docs_snippets.legacy.data_science.download_file import download_file
k_means_iris = dm.define_dagstermill_solid(
"k_means_iris",
script_relative_path("iris-kmeans_2.ipynb"),
input_defs=[InputDefinition("path", str, description="Local path to the Iris dataset")],
)
@pipeline(mode_defs=[ModeDefinition(resource_defs={"io_manager": fs_io_manager})])
def iris_pipeline():
k_means_iris(download_file())
We'll configure the download_file solid with the URL to download the
file from, and the local path at which to save it. This solid has one
output—the path to the downloaded file.
from urllib.request import urlretrieve
from dagster import Field, OutputDefinition, String, solid
from dagster.utils import script_relative_path
@solid(
name="download_file",
config_schema={
"url": Field(String, description="The URL from which to download the file"),
"path": Field(String, description="The path to which to download the file"),
},
output_defs=[
OutputDefinition(
String, name="path", description="The path to which the file was downloaded"
)
],
description=(
"A simple utility solid that downloads a file from a URL to a path using "
"urllib.urlretrieve"
),
)
def download_file(context):
output_path = script_relative_path(context.solid_config["path"])
urlretrieve(context.solid_config["url"], output_path)
return output_path
We'll want to use this path in place of the hardcoded string when we read the csv in to our notebook:
[2]:
ipython3
iris = pd.read_csv(
path,
...
)
We need to make one more change to our notebook so that the path
parameter is injected by the Dagstermill machinery at runtime.
Dagstermill is built on Papermill (3), which uses Jupyter cell tags to identify the cell into which it should inject parameters at runtime. You will need to be running Jupyter 5.0 or later and may need to turn the display of cell tags on (select View > Cell Toolbar > Tags from the Jupyter menu).

Tag the cell you want Dagstermill to replace at runtime with the tag
parameters.
In the source notebook., this cell will look like this:

In the source notebook, we can give our parameters values that are useful for interactive development (say, with a test dataset).
Now we are ready to execute a pipeline that flows the output of arbitrary Python code into a notebook:
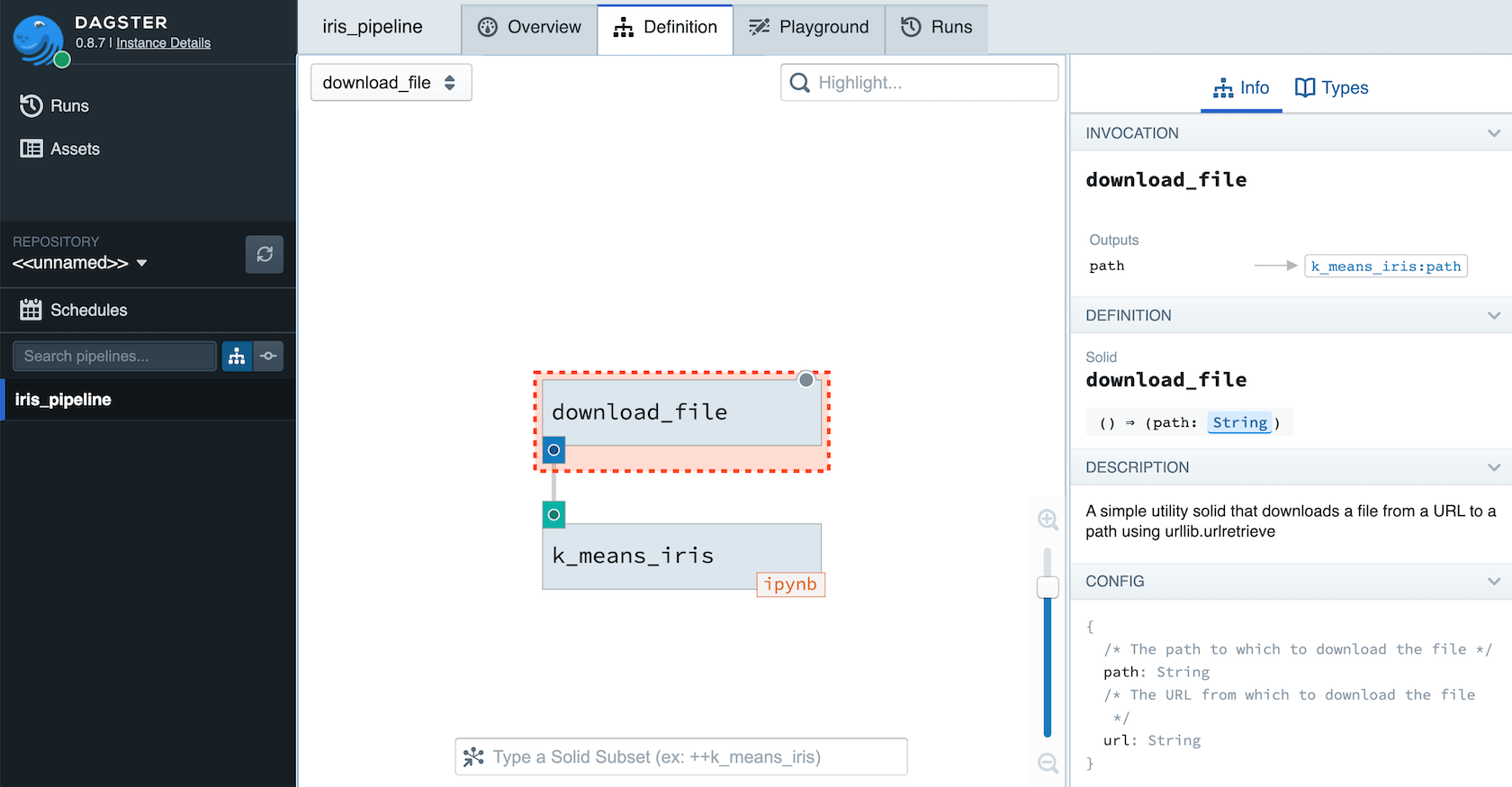
We'll use the following config:
intermediate_storage:
filesystem:
solids:
download_file:
config:
path: "iris.data"
url: "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
When we execute this pipeline with Dagit, the parameters cell in the
source notebook will be dynamically replaced in the output notebook by a
new injected-parameters cell.
The execution log contains the path to the output notebook so that you can access it after execution to examine and potentially debug the output. This path is also displayed in Dagit.
The notebook context#
You'll notice that the injected-parameters cell in your output
notebooks defines a variable called context.
This context object mirrors the execution context object that's available in the body of any other solid's compute function.
As with the parameters that dagstermill injects, you can also construct
a context object for interactive exploration and development by using
the dagstermill.get_context API in the tagged parameters cell of
your input notebook. When dagstermill executes your notebook, this
development context will be replaced with the injected runtime context.
You can use the development context to access solid config and resources, to log messages, and to yield results and other Dagster events just as you would in production. When the runtime context is injected by dagstermill, none of your other code needs to change.
For instance, suppose we want to make the number of clusters (the _k_ in k-means) configurable. We'll change our solid definition to include a config field:
import dagstermill as dm
from dagster import Field, InputDefinition, Int, ModeDefinition, fs_io_manager, pipeline
from dagster.utils import script_relative_path
from docs_snippets.legacy.data_science.download_file import download_file
k_means_iris = dm.define_dagstermill_solid(
"k_means_iris",
script_relative_path("iris-kmeans_2.ipynb"),
input_defs=[InputDefinition("path", str, description="Local path to the Iris dataset")],
config_schema=Field(
Int, default_value=3, is_required=False, description="The number of clusters to find"
),
)
@pipeline(mode_defs=[ModeDefinition(resource_defs={"io_manager": fs_io_manager})])
def iris_pipeline():
k_means_iris(download_file())
In our notebook, we'll stub the context as follows (in the parameters cell):
import dagstermill
from dagster import Field, Int, SolidDefinition
context = dagstermill.get_context(solid_config=3)
Now we can use our config value in our estimator. In production, this will be replaced by the config value provided to the pipeline:
estimator = sklearn.cluster.KMeans(n_clusters=context.solid_config)
Results and custom materializations#
If you'd like to yield a result to be consumed downstream of a
dagstermill notebook, you can call dagstermill.yield_result with the
value of the result and its name. In interactive execution, this is a
no-op, so you don't need to change anything when moving from
interactive exploration and development to production.
You can also yield custom AssetMaterialization objects
(for instance, to tell Dagit where you've saved a plot) by calling dagstermill.yield_event.
References#
- Dua, D. and Graff, C. (2019). Iris Data Set. UCI Machine Learning Repository [https://archive.ics.uci.edu/ml/datasets/iris]. Irvine, CA: University of California, School of Information and Computer Science.
- _Iris flower data set [https://en.wikipedia.org/wiki/Iris_flower_data_set]
- nteract/papermill [https://papermill.readthedocs.io/en/latest/]