
Advanced: Scheduling Pipeline Runs#
Dagster includes a scheduler that allows you to run pipelines at regular intervals, e.g. daily or hourly.
Defining schedules#
As before, we've defined a solid and a pipeline.
import csv
from datetime import datetime, time
from dagster import daily_schedule, pipeline, repository, solid
from dagster.utils import file_relative_path
@solid
def hello_cereal(context, date):
dataset_path = file_relative_path(__file__, "cereal.csv")
context.log.info(dataset_path)
with open(dataset_path, "r") as fd:
cereals = [row for row in csv.DictReader(fd)]
context.log.info(
"Today is {date}. Found {n_cereals} cereals".format(
date=date, n_cereals=len(cereals)
)
)
@pipeline
def hello_cereal_pipeline():
hello_cereal()
Suppose that we need to run our simple cereal pipeline every morning before breakfast, at
6:45 AM. To do this, we'll write a ScheduleDefinition to define our schedule.
We can either directly construct a ScheduleDefinition, or use one of the included schedule
decorators.
In this example, we'll use the @daily_schedule
decorator, which runs a schedule once a day at a specified time.
The decorated function should return the run_config needed to run the schedule at the
specified execution time. The function is passed the datetime for which the schedule is running.
@daily_schedule(
pipeline_name="hello_cereal_pipeline",
start_date=datetime(2020, 6, 1),
execution_time=time(6, 45),
execution_timezone="US/Central",
)
def good_morning_schedule(date):
return {
"solids": {
"hello_cereal": {
"inputs": {"date": {"value": date.strftime("%Y-%m-%d")}}
}
}
}
To complete the picture, we'll need to add the schedule definition to the list of definitions returned from our repository.
@repository
def hello_cereal_repository():
return [hello_cereal_pipeline, good_morning_schedule]
Starting schedules#
Now, we can load Dagit to view the schedule, start and stop it, and monitor the runs it creates:
dagit -f scheduler.py
Our Dagit now displays a Schedules section on the left sidebar.
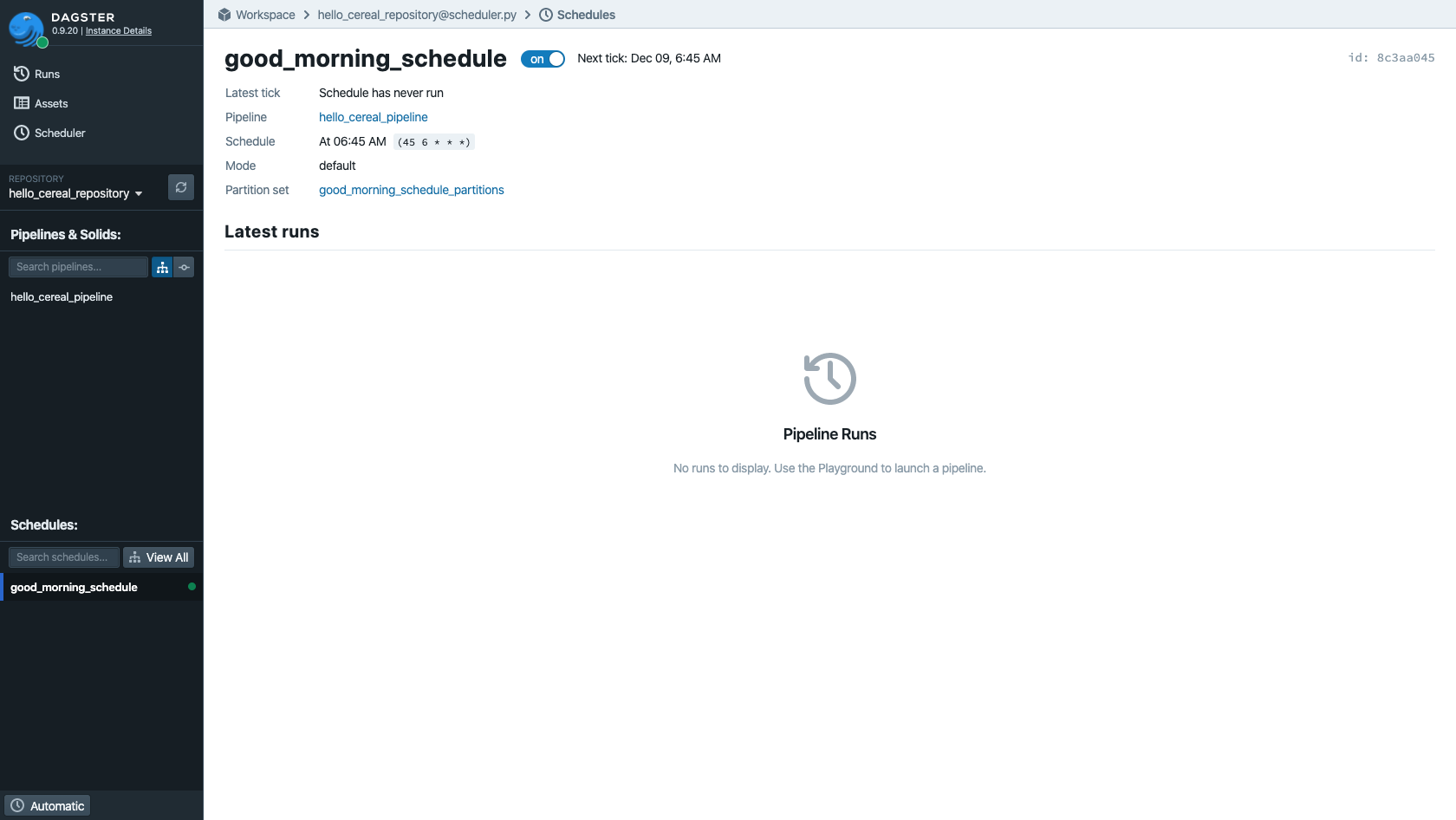
Clicking on good_morning_schedule will take us to the Schedules view. From here, we can
turn on the schedule by pressing the toggle button, at which point dagit will show us that the
schedule is running and will next execute tomorrow at 6:45 AM.
Running the schedule#
Dagster's default scheduler requires you to launch a long-running dagster-daemon process in
addition to Dagit.
dagster-daemon run
This process will periodically check for any running schedules and launch their associated runs. If you leave this process running, it will launch a new run for your schedule each day at the expected time.
Schedule filters#
If you need to customize the times at which the schedule shoule execute, you can pass a function as
the should_execute argument to ScheduleDefinition.
For example, we can define a filter that only returns True on weekdays:
def weekday_filter(_context):
weekno = datetime.today().weekday()
# Returns true if current day is a weekday
return weekno < 5
If we combine this should_execute filter with a
schedule that runs at 6:45am every day, then we'll
have a schedule that runs at 6:45am only on weekdays.
@daily_schedule(
pipeline_name="hello_cereal_pipeline",
start_date=datetime(2020, 6, 1),
execution_time=time(6, 45),
execution_timezone="US/Central",
should_execute=weekday_filter,
)
def good_weekday_morning_schedule(date):
return {
"solids": {
"hello_cereal": {
"inputs": {"date": {"value": date.strftime("%Y-%m-%d")}}
}
}
}