
Configuring Solids#
So far, we've seen a solid whose behavior is the same every time it runs:
@solid
def load_cereals(context):
csv_path = os.path.join(os.path.dirname(__file__), "cereal.csv")
with open(csv_path, "r") as fd:
cereals = [row for row in csv.DictReader(fd)]
context.log.info(f"Found {len(cereals)} cereals".format())
return cereals
In many situations, we'd like to be able to configure solids at run time. For example, we may want whomever is running the pipeline to decide what dataset it operates on. Appropriately parameterized solids are more testable and reusable. Consider the following more generic solid:
@solid(config_schema={"csv_name": str})
def read_csv(context):
csv_path = os.path.join(
os.path.dirname(__file__), context.solid_config["csv_name"]
)
with open(csv_path, "r") as fd:
lines = [row for row in csv.DictReader(fd)]
context.log.info(f"Read {len(lines)} lines")
return lines
Here, rather than hard-coding the value of dataset_path, we use a config option, csv_name.
Let's rebuild a pipeline we've seen before, but this time using our newly parameterized solid.
import csv
import os
from dagster import execute_pipeline, pipeline, solid
@solid(config_schema={"csv_name": str})
def read_csv(context):
csv_path = os.path.join(
os.path.dirname(__file__), context.solid_config["csv_name"]
)
with open(csv_path, "r") as fd:
lines = [row for row in csv.DictReader(fd)]
context.log.info(f"Read {len(lines)} lines")
return lines
@solid
def sort_by_calories(context, cereals):
sorted_cereals = sorted(
cereals, key=lambda cereal: int(cereal["calories"])
)
context.log.info(f'Most caloric cereal: {sorted_cereals[-1]["name"]}')
@pipeline
def configurable_pipeline():
sort_by_calories(read_csv())
Specifying Config for Pipeline Execution#
We can specify config for a pipeline execution regardless of how we execute the pipeline — the Dagit UI, Python API, or the command line:
Dagit Config Editor#
Dagit provides a powerful, schema-aware, typeahead-enabled config editor to enable rapid experimentation with and debugging of parameterized pipeline executions. As always, run:
dagit -f configurable_pipeline.py
Notice that the launch execution button is disabled and the solids are red in the bottom right corner of the Playground.
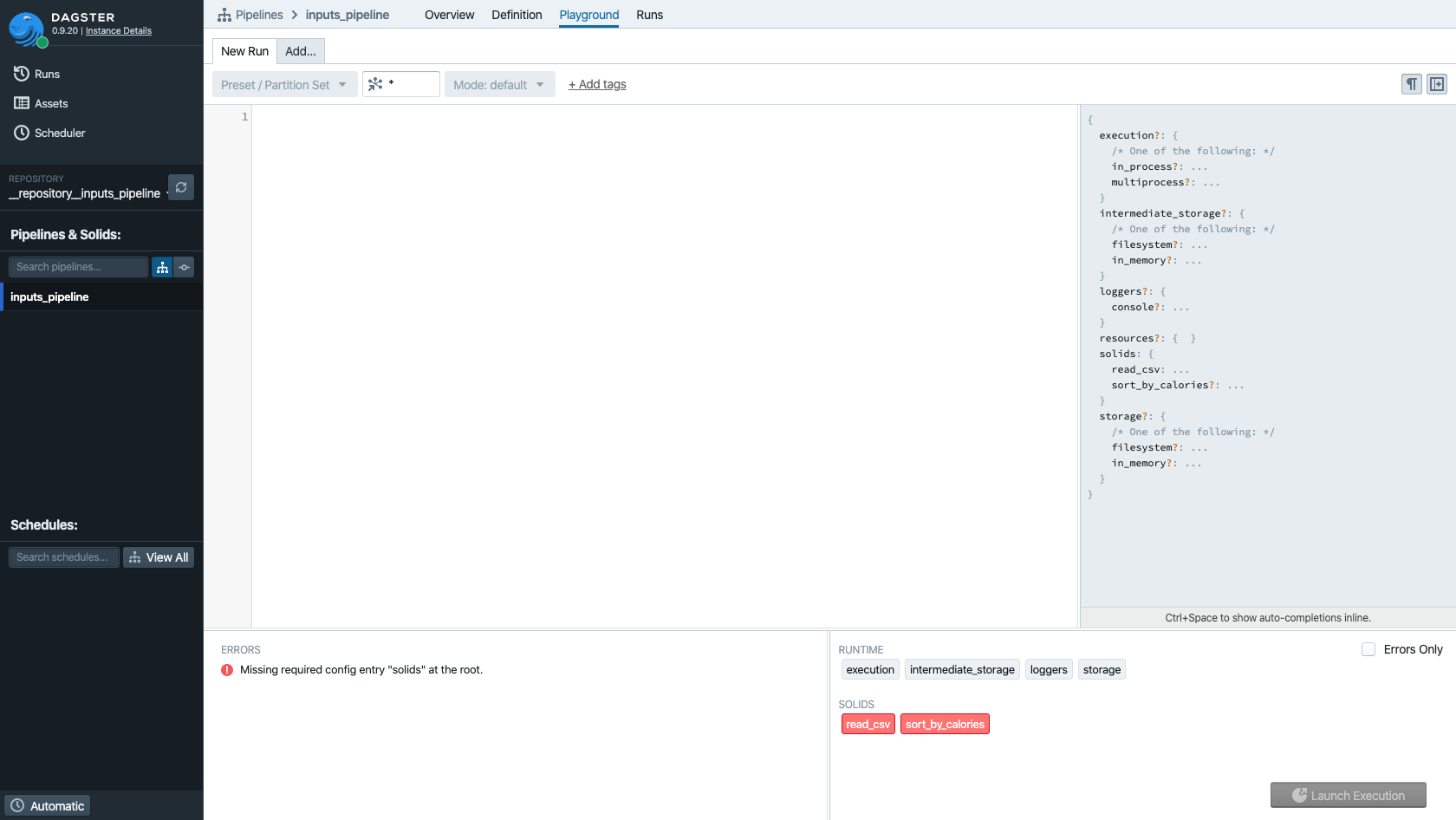
Because Dagit is schema-aware, it knows that this pipeline now requires configuration in order to run without errors. In this case, since the pipeline is relatively trivial, it wouldn't be especially costly to run the pipeline and watch it fail. But when pipelines are complex and slow, it's invaluable to get this kind of feedback up front rather than have an unexpected failure deep inside a pipeline.
Recall that the execution plan, which you will ordinarily see above the log viewer in the Execute tab, is the concrete pipeline that Dagster will actually execute. Without a valid config, Dagster can't construct a parametrization of the logical pipeline—so no execution plan is available for us to preview.
Press Ctrl + Space in order to bring up the typeahead assistant.
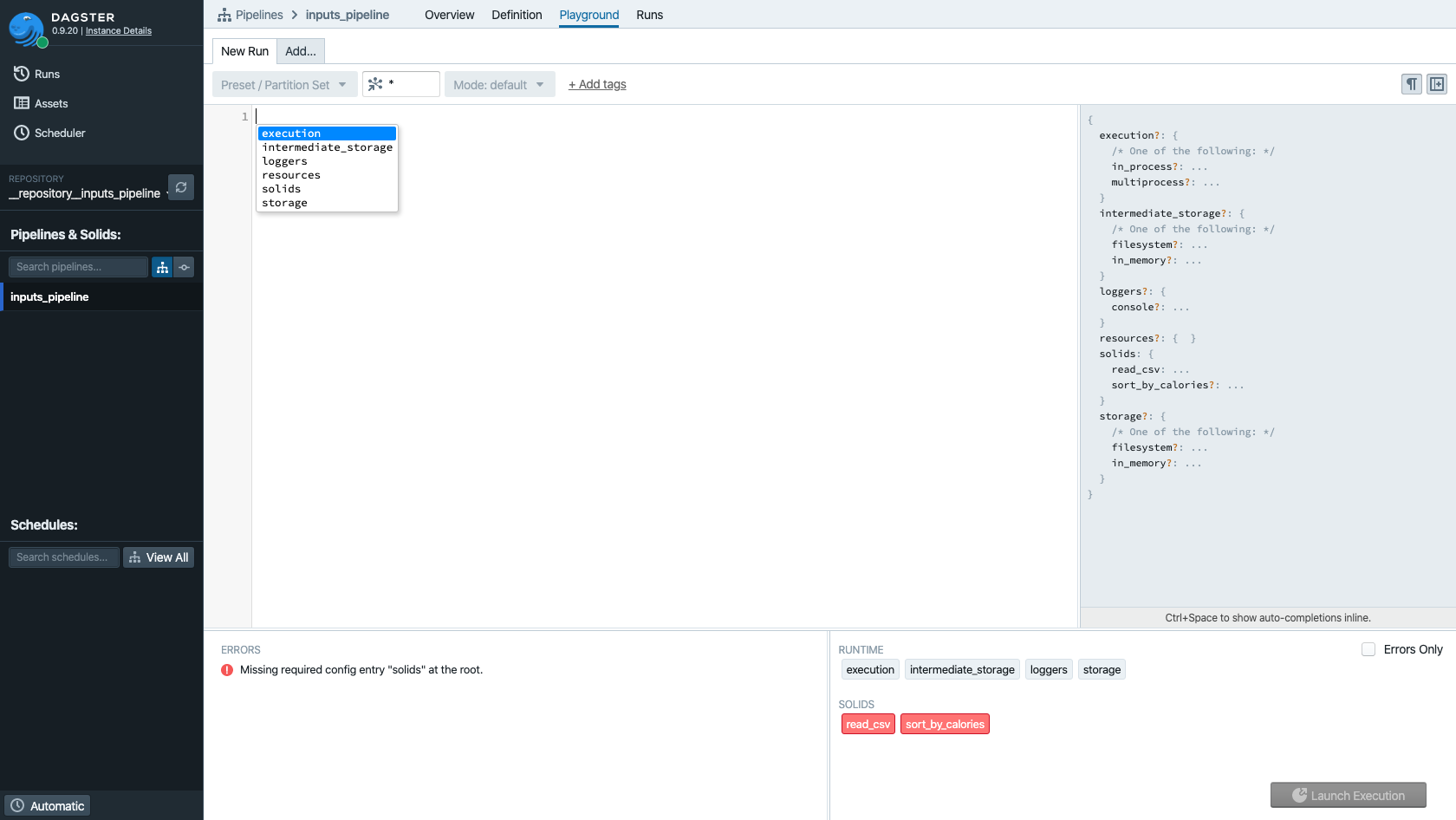
Here you can see all of the sections available in the run config. Don't worry, we'll get to them all later.
Let's enter the config we need in order to execute our pipeline.

Note that as you type and edit the config, the config minimap hovering on the right side of the editor pane changes to provide context—you always know where in the nested config schema you are while making changes.
Config in Python API#
We previously encountered the execute_pipeline()function. Pipeline run config is specified by the second
argument to this function, which must be a dict.
This dict contains all of the user-provided configuration with which to execute a pipeline. As such,
it can have a lot of sections, but we'll only use one of
them here: per-solid configuration, which is specified under the key solids:
run_config = {
"solids": {"read_csv": {"config": {"csv_name": "cereal.csv"}}}
}
The solids dict is keyed by solid name, and each solid is configured by a dict that may itself
have several sections. In this case, we are interested in the config section.
Now you can pass this run config to execute_pipeline():
result = execute_pipeline(configurable_pipeline, run_config=run_config)
YAML fragments and Dagster CLI#
When executing pipelines with the Dagster CLI, we'll need to provide the run config in a file. We use YAML for the file-based representation of configuration, but the values are the same as before:
solids:
read_csv:
config:
csv_name: "cereal.csv"
We can pass config files in this format to the Dagster CLI tool with the -c flag.
dagster pipeline execute -f configurable_pipeline.py -c run_config.yaml
In practice, you might have different sections of your run config in different yaml files—if,
for instance, some sections change more often (e.g. in test and prod) while other are more static.
In this case, you can set multiple instances of the -c flag on CLI invocations, and the CLI tools
will assemble the YAML fragments into a single run config.