Advanced: Solid Re-use and Composition#
Abstracting business logic into reusable, configurable solids is one important step towards making data applications like other software applications.
Reusable Solids#
Solids are intended to abstract chunks of business logic, but abstractions aren't very meaningful unless they can be reused.
Our conditional outputs pipeline included a lot of repeated
code—sort_hot_cereals_by_calories and sort_cold_cereals_by_calories, for instance. In
general, it's preferable to build pipelines out of a relatively restricted set of well-tested
library solids, using config liberally to parametrize them. You'll certainly have your own version
of read_csv, for instance, and Dagster includes libraries like
dagster_aws and
dagster_spark to wrap and abstract interfaces with
common third party tools.
Let's replace sort_hot_cereals_by_calories and sort_cold_cereals_by_calories by two aliases of
the same library solid:
@solid(config_schema=String)
def sort_cereals_by_calories(context, cereals):
sorted_cereals = sorted(
cereals, key=lambda cereal: int(cereal["calories"])
)
context.log.info(
"Least caloric {cereal_type} cereal: {least_caloric}".format(
cereal_type=context.solid_config,
least_caloric=sorted_cereals[0]["name"],
)
)
@pipeline
def reusable_solids_pipeline():
hot_cereals, cold_cereals = split_cereals(read_csv())
sort_hot_cereals = sort_cereals_by_calories.alias("sort_hot_cereals")
sort_cold_cereals = sort_cereals_by_calories.alias("sort_cold_cereals")
sort_hot_cereals(hot_cereals)
sort_cold_cereals(cold_cereals)
You'll see that Dagit distinguishes between the two invocations of the single library solid and the solid's definition. The invocation is named and bound via a dependency graph to other invocations of other solids. The definition is the generic, reusable piece of logic that is invoked many times within this pipeline.
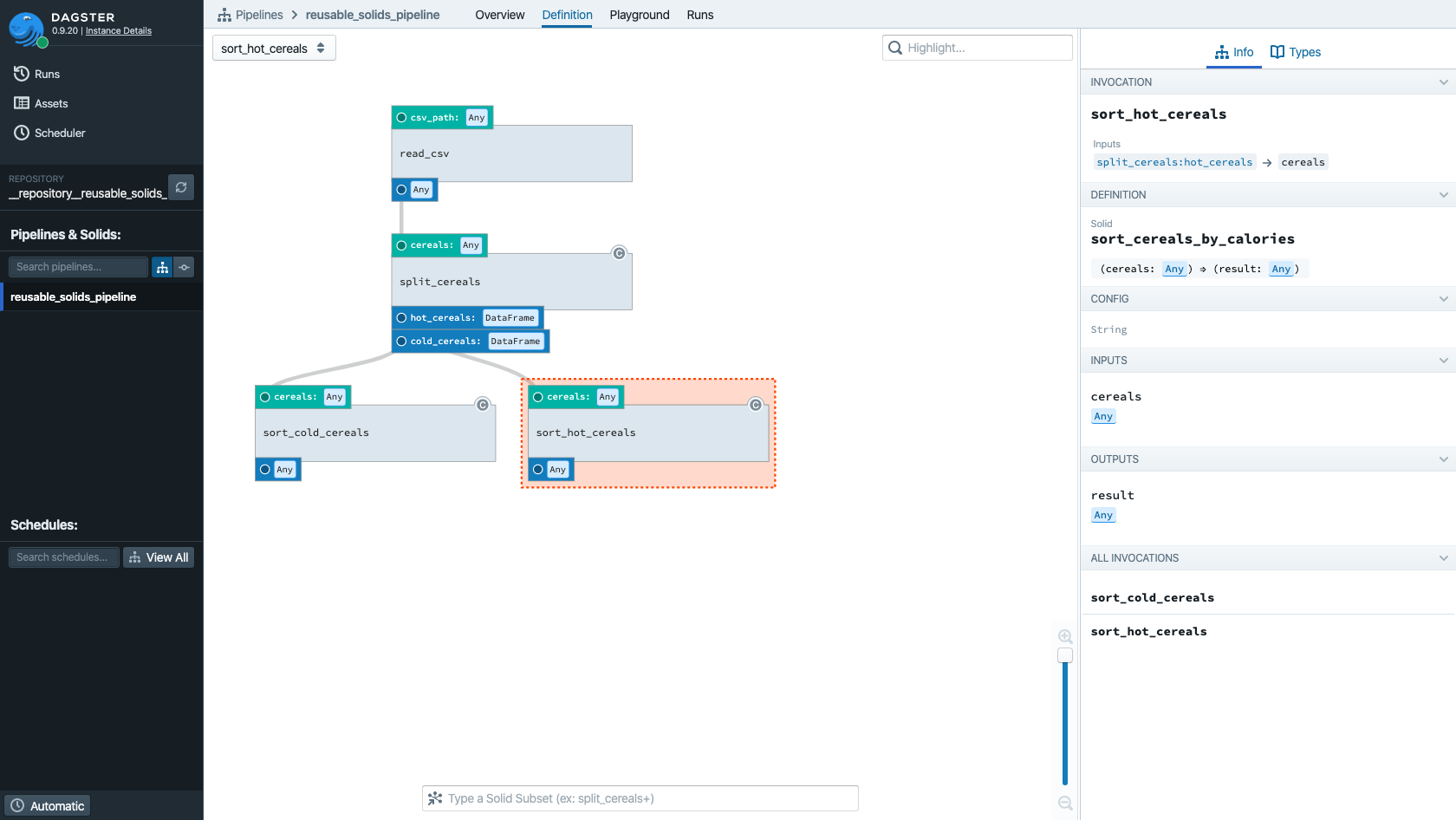
Configuring solids also uses the aliases, as in the following YAML:
solids:
read_csv:
inputs:
csv_path:
value: "cereal.csv"
sort_cold_cereals:
config: "cold"
sort_hot_cereals:
config: "hot"
Composite Solids#
The other basic facility that we expect from software in other domains is composability—the ability to combine building blocks into larger functional units.
Composite solids can be used to organize and refactor large or complicated pipelines, abstracting away complexity, as well as to wrap reusable general-purpose solids together with domain-specific logic.
As an example, let's compose two instances of a complex, general-purpose read_csv solid along with
some domain-specific logic for the specific purpose of joining our cereal dataset with a lookup
table providing human-readable names for the cereal manufacturers.
@composite_solid
def load_cereals() -> DataFrame:
read_cereals = read_csv.alias("read_cereals")
read_manufacturers = read_csv.alias("read_manufacturers")
return join_cereal(read_cereals(), read_manufacturers())
Defining a composite solid is similar to defining a pipeline, except
that we use the @composite_solid decorator
instead of @pipeline. Dagit has
sophisticated facilities for visualizing composite solids:
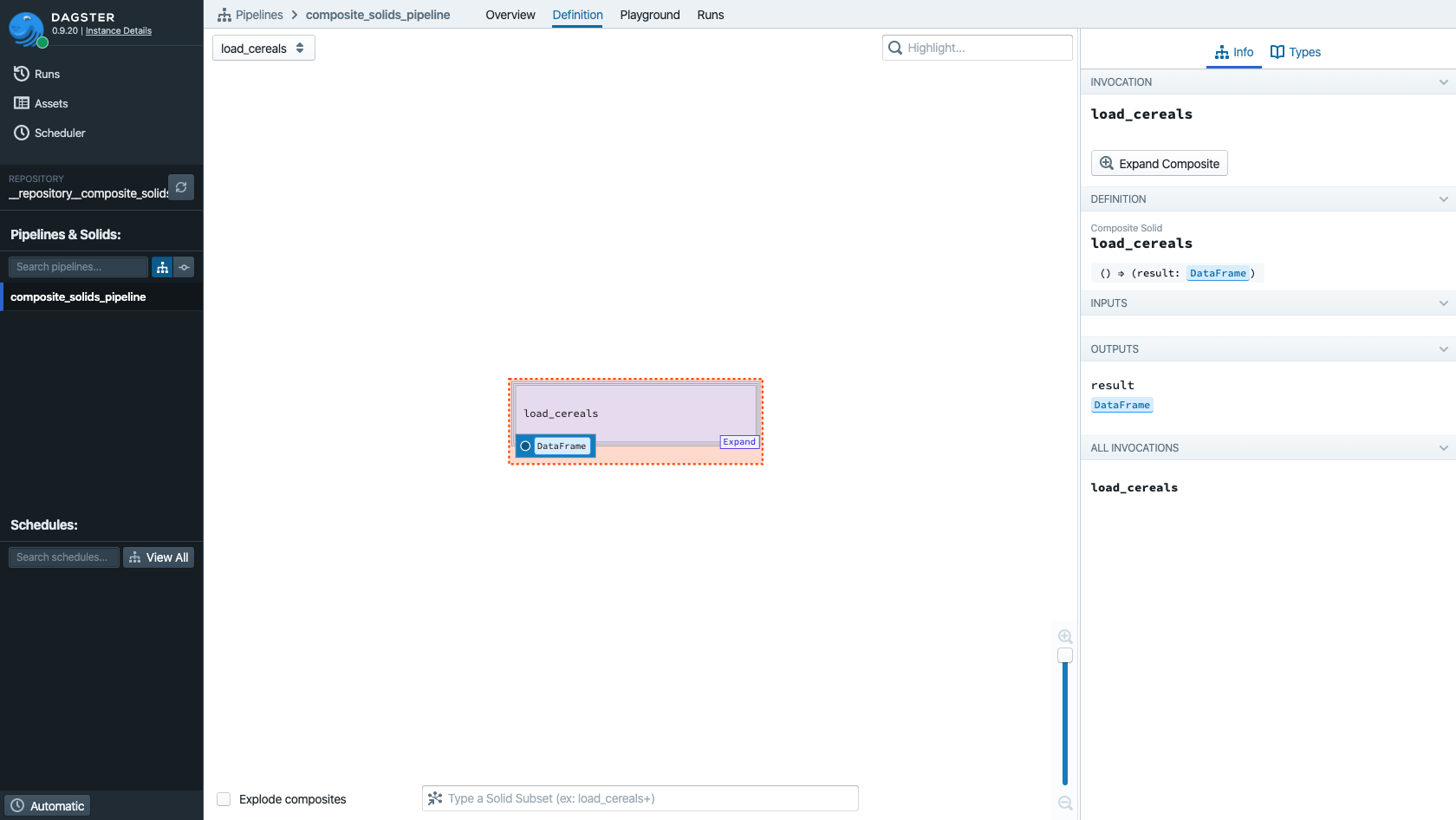
All of the complexity of the composite solid is hidden by default, but we can expand it at will by clicking into the solid (or on the "Expand" button in the right-hand pane):
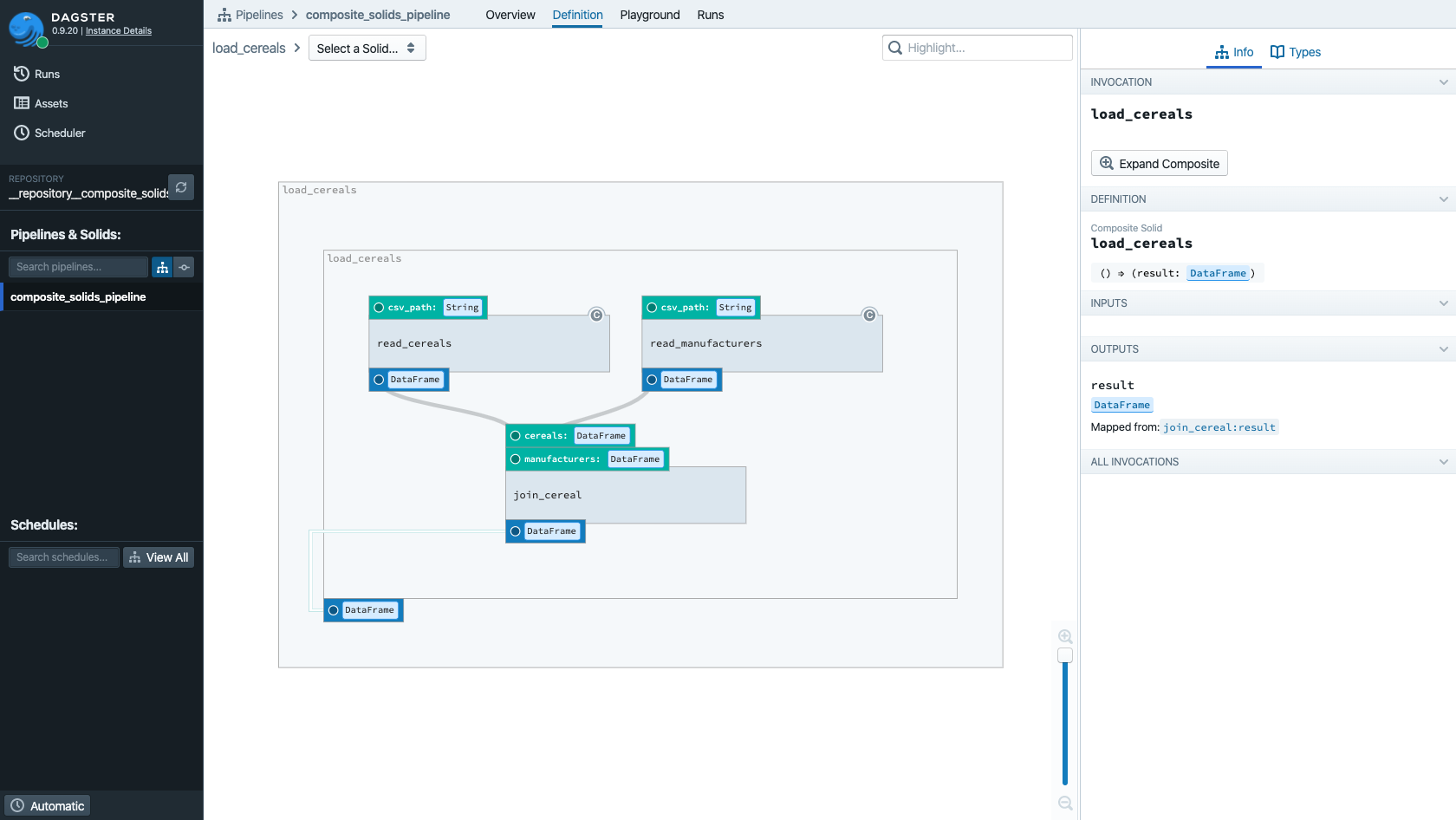
Note the line indicating that the output of join_cereal is returned as the output of the composite
solid as a whole.
Config for the individual solids making up the composite is nested, as follows:
solids:
load_cereals:
solids:
read_cereals:
inputs:
csv_path:
value: "cereal.csv"
read_manufacturers:
config:
delimiter: ";"
inputs:
csv_path:
value: "manufacturers.csv"
When we execute this pipeline, Dagit includes information about the nesting of individual execution steps within the composite: