Advanced: Dagster Types#
Verifying Solid Outputs and Inputs#
Dagster lets developers express what they expect their solid inputs and outputs to look like through Dagster Types.
The dagster type system is gradual and optional - pipelines can run without types specified explicitly, and specifying types in some places doesn't require that types be specified everywhere.
Dagster type-checking happens at solid execution time - each type defines a type_check_fn that knows how to check whether values match what it expects.
- When a type is specified for a solid's input, then the type check occurs immediately before the solid is executed.
- When a type is specified for a solid's output, then the type check occurs immediately after the solid is executed.
Let's look back at our simple read_csv solid.
@solid
def read_csv(context, csv_path: str):
csv_path = os.path.join(os.path.dirname(__file__), csv_path)
with open(csv_path, "r") as fd:
lines = [row for row in csv.DictReader(fd)]
context.log.info(f"Read {len(lines)} lines")
return lines
The lines object returned by Python's built-in csv.DictReader is a list of
collections.OrderedDict, each of which represents one row of the dataset:
[
OrderedDict([
('name', '100% Bran'), ('mfr', 'N'), ('type', 'C'), ('calories', '70'), ('protein', '4'),
('fat', '1'), ('sodium', '130'), ('carbo', '5'), ('sugars', '6'), ('potass', '280'),
('vitamins', '25'), ('shelf', '3'), ('weight', '1'), ('cups', '0.33'),
('rating', '68.402973')
]),
OrderedDict([
('name', '100% Natural Bran'), ('mfr', 'Q'), ('type', 'C'), ('calories', '120'),
('protein', '3'), ('fat', '5'), ('sodium', '15'), ('fiber', '2'), ('carbo', '8'),
('sugars', '8'), ('potass', '135'), ('vitamins', '0'), ('shelf', '3'), ('weight', '1'),
('cups', '1'), ('rating', '33.983679')
]),
...
]
This is a simple representation of a "data frame", or a table of data. We'd like to be able to use
Dagster's type system to type the output of read_csv, so that we can do type checking when we
construct the pipeline, ensuring that any solid consuming the output of read_csv expects to
receive data in this format.
Constructing a Dagster Type#
To do this, we'll construct a DagsterType that verifies an object is a list of dictionaries.
def is_list_of_dicts(_, value):
return isinstance(value, list) and all(
isinstance(element, dict) for element in value
)
SimpleDataFrame = DagsterType(
name="SimpleDataFrame",
type_check_fn=is_list_of_dicts,
description="A naive representation of a data frame, e.g., as returned by csv.DictReader.",
)
Now we can annotate the rest of our pipeline with our new type:
@solid(output_defs=[OutputDefinition(SimpleDataFrame)])
def read_csv(context, csv_path: str):
csv_path = os.path.join(os.path.dirname(__file__), csv_path)
with open(csv_path, "r") as fd:
lines = [row for row in csv.DictReader(fd)]
context.log.info(f"Read {len(lines)} lines")
return lines
@solid(input_defs=[InputDefinition("cereals", SimpleDataFrame)])
def sort_by_calories(context, cereals):
sorted_cereals = sorted(cereals, key=lambda cereal: cereal["calories"])
context.log.info(f'Most caloric cereal: {sorted_cereals[-1]["name"]}')
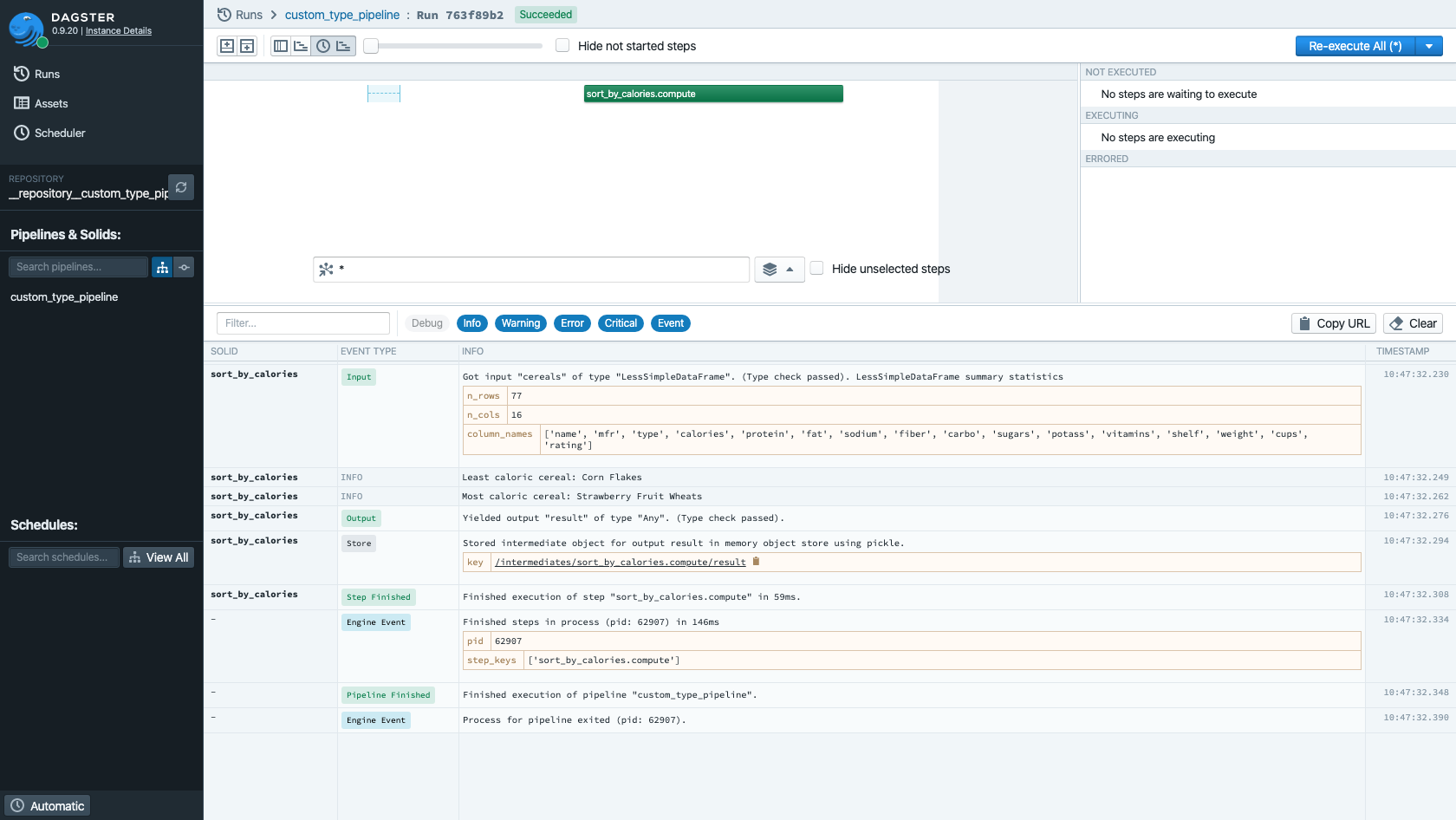
The type metadata now appears in Dagit and the system will ensure the input and output to this solid
indeed match the criteria for SimpleDataFrame. As usual, run:
dagit -f custom_types.py
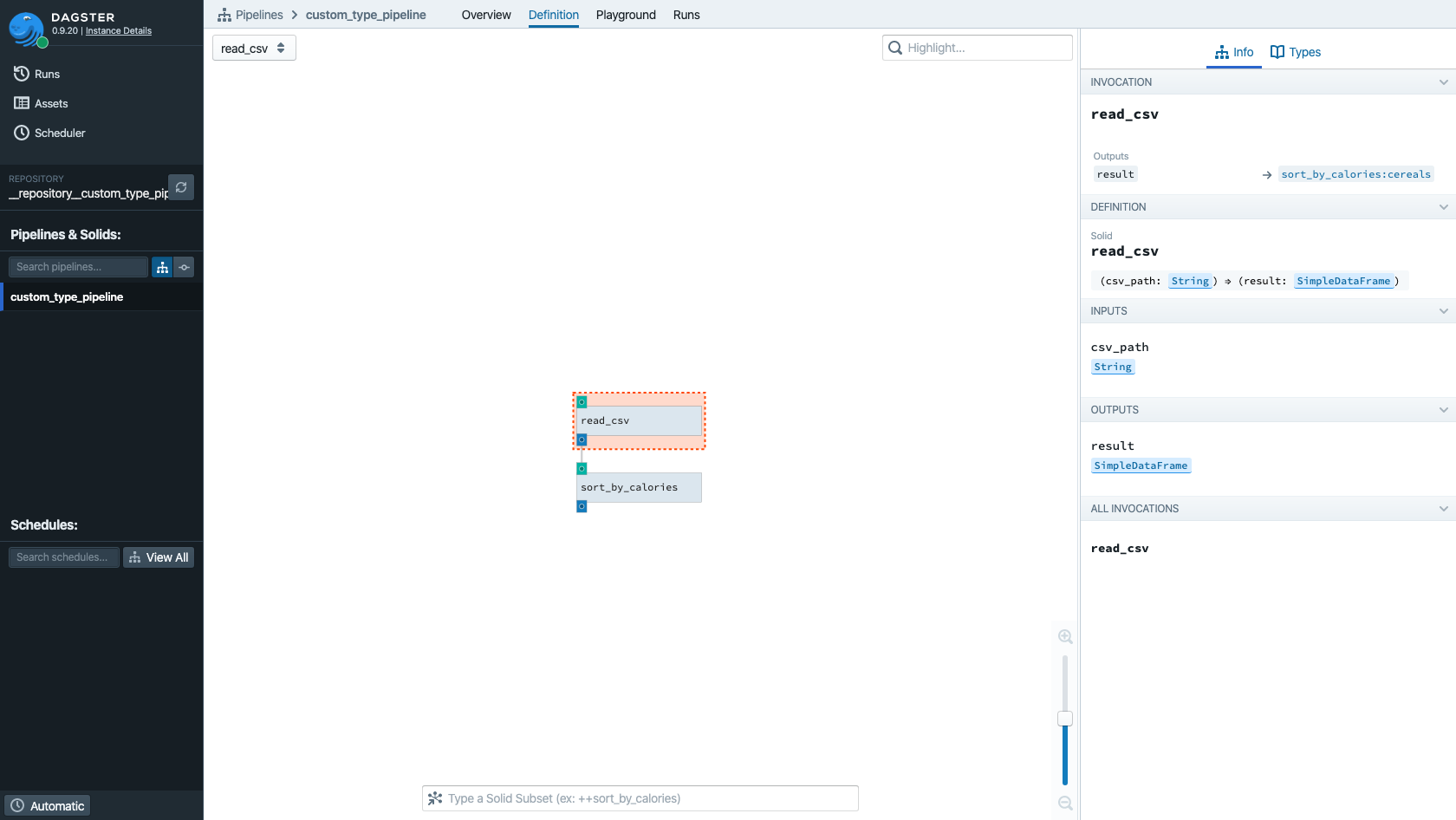
You can see that the output of read_csv (which by default has the name result) is marked to be
of type SimpleDataFrame.
When Type Checks Fail#
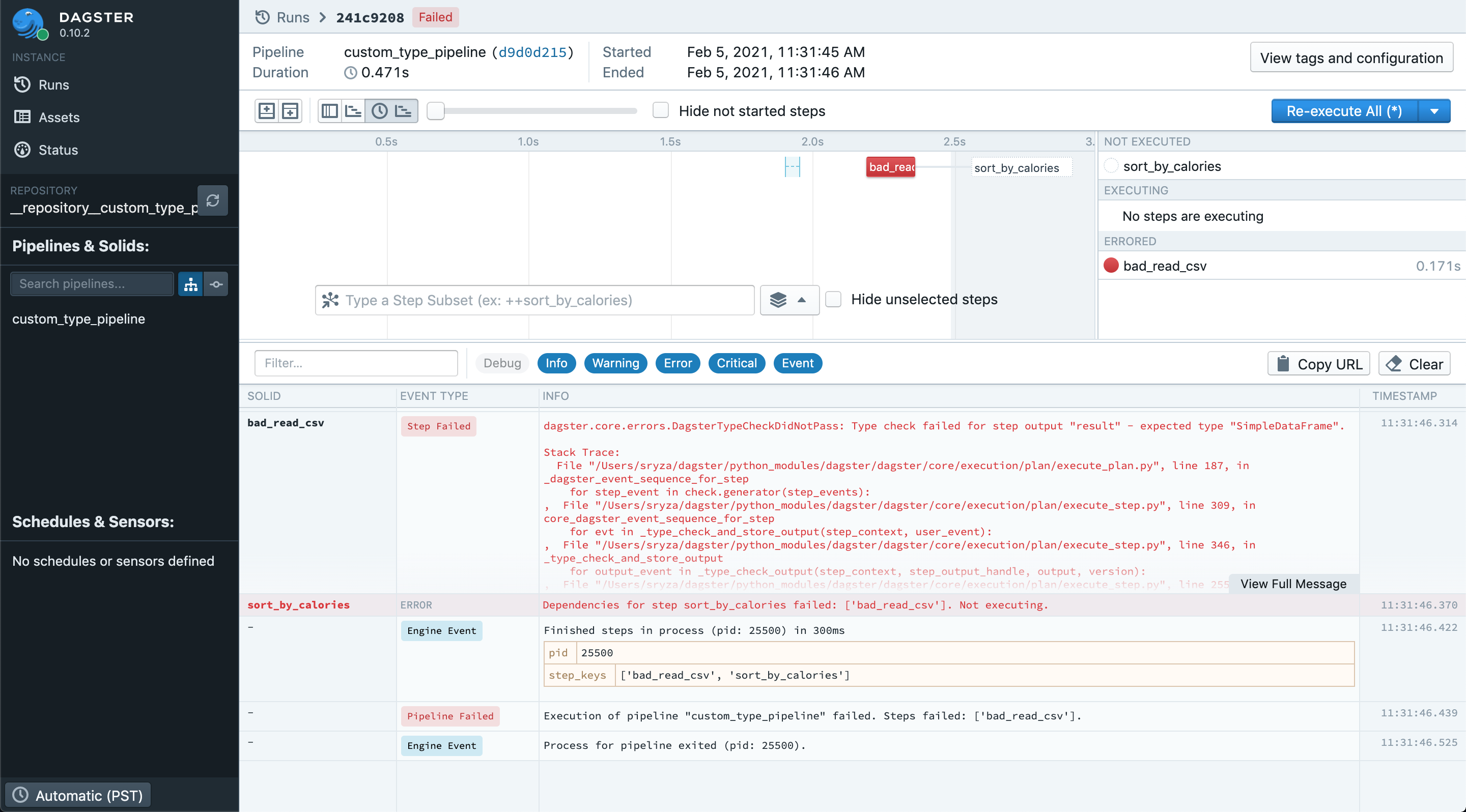
Now, if our solid logic fails to return the right type, we'll see a type check failure, which will
fai the pipeline. Let's replace our read_csv solid with the following bad logic:
@solid(output_defs=[OutputDefinition(SimpleDataFrame)])
def bad_read_csv(context):
csv_path = os.path.join(os.path.dirname(__file__), "cereal.csv")
with open(csv_path, "r") as fd:
lines = [row for row in csv.DictReader(fd)]
context.log.info(f"Read {len(lines)} lines")
return ["not_a_dict"]
When we run the pipeline with this solid, we'll see an error in your terminal like:
2021-02-05 11:31:46 - dagster - ERROR - custom_type_pipeline - 241c9208-6367-474f-8625-5b64fbf74568 - 25500 - bad_read_csv - STEP_FAILURE - Execution of step "bad_read_csv" failed.
dagster.core.errors.DagsterTypeCheckDidNotPass: Type check failed for step output "result" - expected type "SimpleDataFrame".
We will also see the error message in Dagit:
Metadata and Custom Type Checks#
Custom types can also yield metadata about the type check. For example, in the case of our data
frame, we might want to record the number of rows and columns in the dataset when our type checks
succeed, and provide more information about why type checks failed when they fail. User-defined type
check functions can optionally return a TypeCheck object that
contains metadata about the success or failure of the type check. Let's see how to use this to emit
some summary statistics about our DataFrame type:
def less_simple_data_frame_type_check(_, value):
if not isinstance(value, list):
return TypeCheck(
success=False,
description=(
"LessSimpleDataFrame should be a list of dicts, got "
"{type_}"
).format(type_=type(value)),
)
fields = [field for field in value[0].keys()]
for i in range(len(value)):
row = value[i]
if not isinstance(row, dict):
return TypeCheck(
success=False,
description=(
"LessSimpleDataFrame should be a list of dicts, "
"got {type_} for row {idx}"
).format(type_=type(row), idx=(i + 1)),
)
row_fields = [field for field in row.keys()]
if fields != row_fields:
return TypeCheck(
success=False,
description=(
"Rows in LessSimpleDataFrame should have the same fields, "
"got {actual} for row {idx}, expected {expected}"
).format(actual=row_fields, idx=(i + 1), expected=fields),
)
return TypeCheck(
success=True,
description="LessSimpleDataFrame summary statistics",
metadata_entries=[
EventMetadataEntry.text(
str(len(value)),
"n_rows",
"Number of rows seen in the data frame",
),
EventMetadataEntry.text(
str(len(value[0].keys()) if len(value) > 0 else 0),
"n_cols",
"Number of columns seen in the data frame",
),
EventMetadataEntry.text(
str(list(value[0].keys()) if len(value) > 0 else []),
"column_names",
"Keys of columns seen in the data frame",
),
],
)
A TypeCheck must include a success
argument describing whether the check passed or failed, and may include a description and/or a list
of EventMetadataEntry objects. You should use the static
constructors on EventMetadataEntry to construct these
objects, which are flexible enough to support arbitrary metadata in JSON or Markdown format.
Dagit knows how to display and archive structured metadata of this kind for future review: